Meta presenta nueva IA capaz de generar imágenes en medio de un debate regulatorio

Una Inteligencia Artificial más parecida a un humano. Como si todos los desarrollos de IA actuales no fueran ya lo bastante parecidos, Meta, empresa matriz de Facebook e Instagram, ha presentado un modelo de aprendizaje automático con una arquitectura que pretende resolver limitaciones de los desarrollos actuales.
Su nombre es Image Joint Embedding Predictive Architecture, también conocido como I-JEPA, y, según la empresa, es el primer modelo de IA basado en un componente clave de la visión de LeCUn, científico jefe de la IA de Meta cuya visión es “crear máquinas que puedan aprender modelos internos de cómo funciona el mundo para que puedan aprender mucho más rápido”.
Today we're releasing our work on I-JEPA — self-supervised computer vision that learns to understand the world by predicting it. It's the first model based on a component of @ylecun's vision to make AI systems learn and reason like animals and humans.
— Meta AI (@MetaAI) June 13, 2023
Details
A través de un comunicado , la empresa dijo que las pruebas iniciales evidencian que I-JEPA exhibe un desempeño sobresaliente en diversas labores relacionadas con la visión artificial. Además, “destaca por ser considerablemente más eficiente que otros modelos de vanguardia”, ya que requiere apenas una décima parte de los recursos computacionales para su entrenamiento. Meta ha compartido abiertamente el código y el modelo de entrenamiento, y presentará I-JEPA en la próxima conferencia de visión por computadora.
I-JEPA será capaz de generar imágenes y textos a partir de predicciones de ciertas partes del contenido como una imágen o un fragmento de texto, una acción muy parecida al razonamiento humano. “Debido a que no implica colapsar representaciones de múltiples vistas/aumentos de una imagen en un solo punto, la esperanza es que JEPA evite los sesgos y problemas asociados con otro método ampliamente utilizado llamado entrenamiento previo basado en la invariancia”, escribió la empresa.
Además, estas predicciones serán dirigidas a un nivel de abstracción, en lugar de predecir valores de pixeles, para “aprender directamente” representaciones útiles. Los métodos generativos, predicen en el espacio de píxel/token, mientras que I-JEPA pretende utilizar objetivos de predicción abstractos para los que se eliminan potencialmente los detalles innecesarios a nivel de píxel, lo que lleva al modelo a aprender más características semánticas.
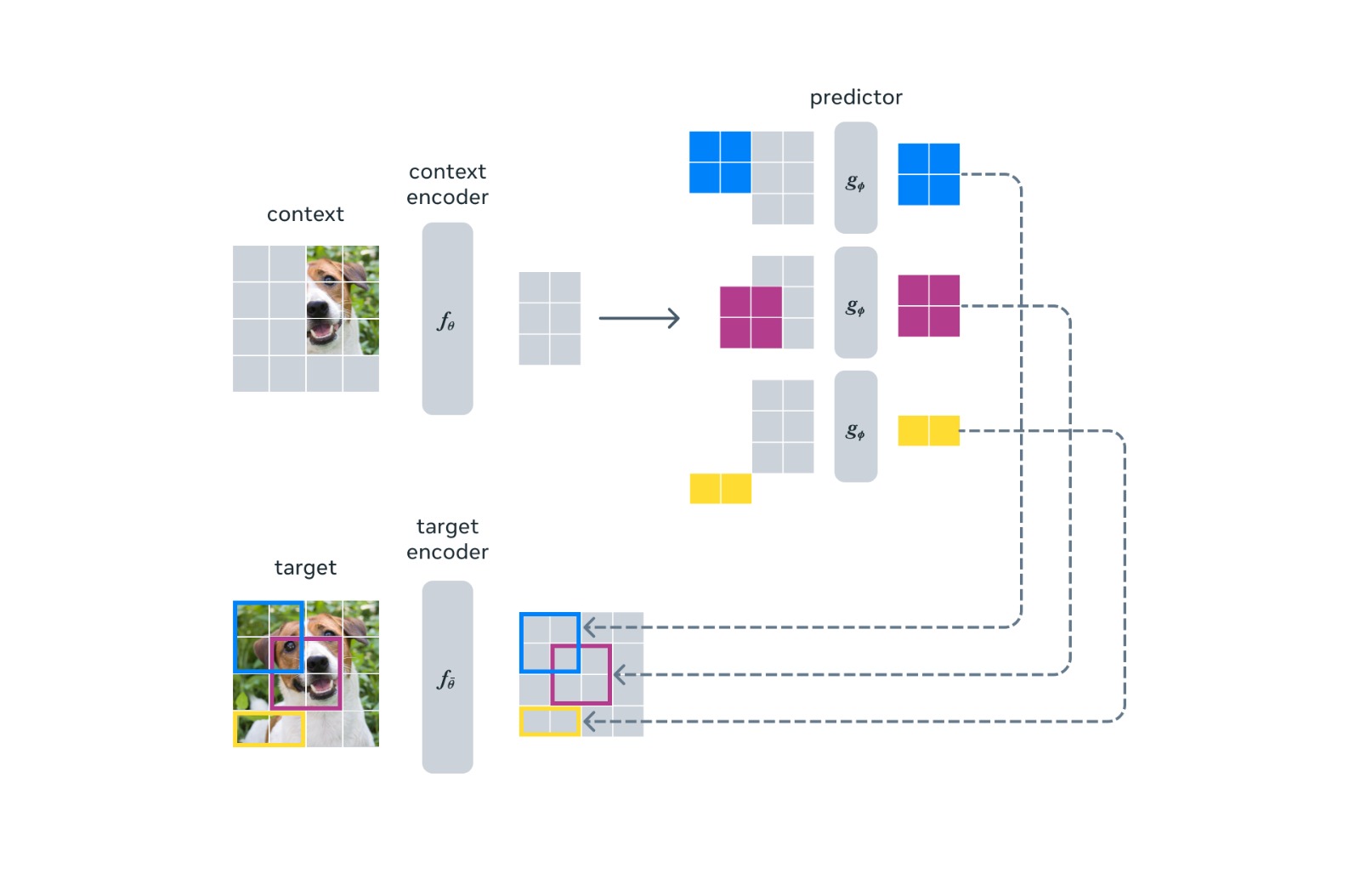
La arquitectura de I-JEPA utiliza un solo bloque de contexto para predecir las representaciones de varios bloques objetivo que se originan en la misma imagen. (Imagen: Meta)
Los modelos generativos, como DALL-E y GPT, han sido concebidos para realizar predicciones minuciosas. Por ejemplo, durante el proceso de entrenamiento, una porción de texto o imagen es ocultada y el modelo trata de anticipar las palabras o píxeles exactos que faltan. El desafío de tratar de completar toda la información radica en que en la impredecibilidad de la información, por lo que, el modelo a menudo se encuentra atrapado entre múltiples resultados posibles.
Esta circunstancia implica que los modelos generativos encuentran dificultades para generar objetos detallados, e incluso llegan a presentar imágenes completamente desproporcionadas. Sin embargo, la arquitectura de la nueva IA de Meta, busca una interpretación todavía mayor de sus datos, haciendo que sesgos como este ocurran con menos frecuencia y más exactitud en el producto arrojado.
El agujero de la regulación sigue ahí
Modelos generativos como Dall-E y Midjourney, se entrenan utilizando técnicas de aprendizaje profundo y grandes conjuntos de datos, y durante este proceso se reúnen una gran cantidad de imágenes representativas que se utilizarán para entrenar el modelo. Estas imágenes pueden provenir de diversas fuentes, como bases de datos públicas, colecciones en línea, o incluso imágenes generadas específicamente para el entrenamiento.
Después, las imágenes se someten a un proceso de preprocesamiento para normalizar el tamaño, el formato y otras características relevantes. Además, se pueden aplicar técnicas de aumento de datos, como rotación, recorte y cambios de iluminación, para aumentar la diversidad del conjunto de datos y mejorar la capacidad de generalización del modelo.
Durante estas tareas, ha sido polémico el uso de las imágenes, pues aún no existe un marco legal que regule el contenido con el que modelos de IA son entrenados. Un ejemplo de este debate, fue la demanda de Getty Images hacia los creadores de Stable Diffusion, un modelo de aprendizaje automático que también es generador de imágenes.
En febrero de este año, la reconocida agencia de fotografía y proveedor de contenido visual demandó a Stability AI, creadores de Stable Diffusion por una "infracción descarada de la propiedad intelectual de Getty Images en una escala asombrosa". La agencia afirma que Stability AI copió más de 12 millones de imágenes de su base de datos "sin permiso... o compensación... como parte de sus esfuerzos para construir un negocio competitivo", y que la puesta en marcha ha infringido tanto los derechos de autor como la marca registrada de la empresa, según un informe de The Verge.

La alteración de las fotografías fue un punto tratado en la demanda. (Imagen: Documento de Getty Images)
Sin embargo, este terreno aún no se encuentra regulado, por lo que el caso fue tratado de una manera lenta, e incluso a pesar de estar muy bien sustentado, el panorama continúa siendo incierto. Las leyes de propiedad intelectual siguen siendo únicamente legisladas cuando el autor se considera una persona, aunque aún no se definen los casos en el que el autor sea una IA o el protocolo a seguir cuando estos desarrollos utilicen imágenes con derechos de autor.
Por su parte, Meta no ha revelado exactamente con qué tipo de imágenes I-JEPA está entrenándose, aunque sí asegura que gracias a este modelo no solamente podrán realizarse imágenes, sino concretarse diferentes tareas, entre ellas la creación de materiales de marketing, el diseño de productos y la generación de arte. La compañía también está explorando formas de usar I-JEPA para mejorar sus productos existentes, como la función de etiquetado de fotos de Facebook.
Será interesante conocer cómo domina esta herramienta el mercado del copyright, aunque su método sea diferente al de Dall-E gracias a la comprensión semántica de imágenes, que también ofrecerá eficiencia computacional. “A diferencia de otros enfoques que requieren múltiples vistas o aumentos de datos computacionalmente intensivos, I-JEPA logra fuertes representaciones semánticas listas para usar utilizando solo un vista única de la imagen”, describe.
En realidad Meta apenas comienza a explorar el ámbito de la IA aplicada a herramientas precisas, incluso esta herramienta, a diferencia de otros productos, promete desbloquear un potencial enorme y abrir paso a una nueva forma de crear imágenes, aunque la regulación de la IA se encuentra cada vez más presente, pues muchos son los países que ya han dado un primer paso hacia la regulación, como las medidas adoptadas por Chat GPT, de Open AI, debido a los riesgos de seguridad y de uso de datos que su plataforma presentó en Europa.
A medida que el entusiasmo crece, las dudas también. Se espera que en esta semana, Meta pueda probar el desarrollo en la próxima conferencia CVPR 2023.





